In the previous [post](https://steemit.com/steemstem/@scienceangel/lab-diaries-4-whole-transcriptome-and-proteome-analysis-by-rna-sequencing-and-tmt-ms) I have explained how we obtained our RNA-seq and TMT-MS data, and today I will introduce you to a very useful tool for analysis of such large-scale biological data. <center>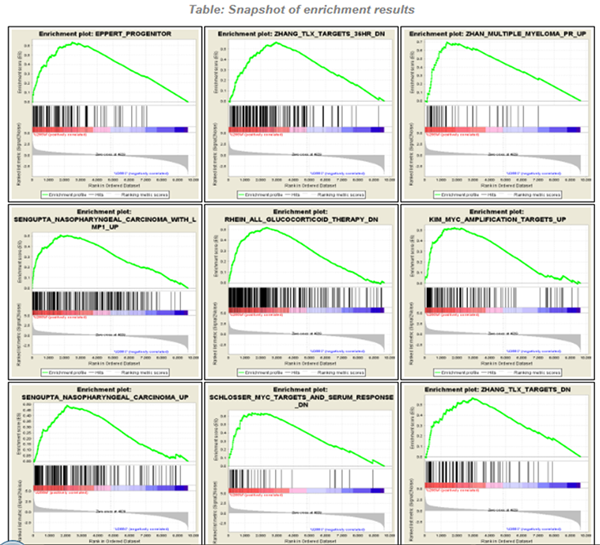</center> <center>*Screenshot of GSEA results*</center> ## Finding a meaning in your meaningless data _________ Imagine that you've analysed your RNA seq data, and after analysis you saw that you have more than 5000 differentially expressed genes after you have induced expression of a particular gene in your cells... **What the .... am I supposed to do with that information?!?** <div class=pull-left> In each of our cells there are many, many (and one more time - many!) signal transduction pathways that include thousands of proteins, which are tightly regulated to keep our cells alive and functioning. In cancer cells, due to the activation of oncogenes, many of those pathways are deregulated to provide advantages to cancer cells over normal cells. These changes make them immortal, allowing them to grow indefinitely and eventually to migrate and invade other parts of our body. </div> <div class=pull-right> <center>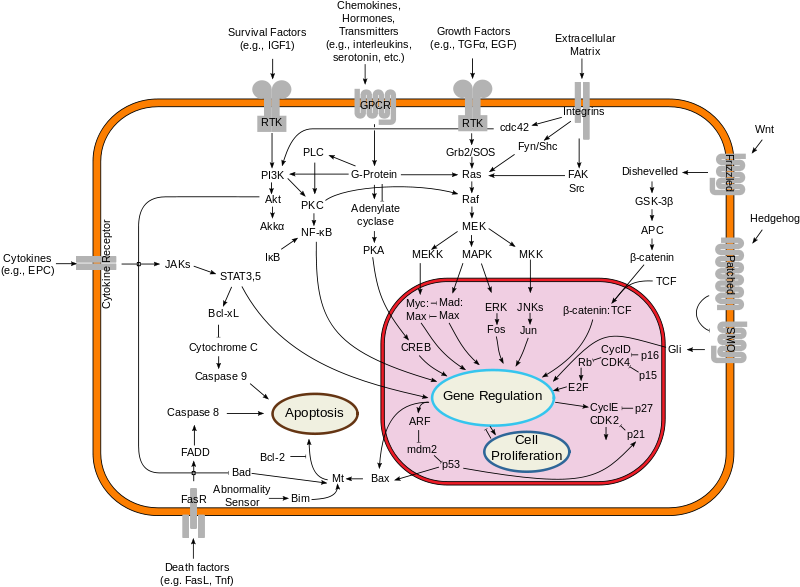</center> <center> <sup>[Simplified representation of major signal transduction pathways](https://en.wikipedia.org/wiki/File:Signal_transduction_pathways.svg), by cybertory, [CC BY-SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/deed.en)</sup> </center> </div> <br><br><br><br> <br><br><br><br><br><br><br><br><br><br> Now let's get back to our "small" problem of having 5000 over- or under-expressed genes in our cells with high expression of an oncogene, compared to same cells with low expression of the same oncogene. How can we know in which of these signal transduction pathways are all those genes included, and what is the biological meaning of those 5000 genes being changed? Well, we could just go and analyse one by one gene and if we are lucky, just before retirement we would succeed in analyzing them all and finally publish our results 30 years after we performed an actual experiment... ### Gene Set Enrichment Analysis (GSEA) _________ ... or we could just use **Gene Set Enrichment Analysis (GSEA)** and publish our results in only 3 years, yeah! If we're lucky... I mean, if we have any good results actually... Never mind, just keep reading... GSEA is a very useful computational tool for interpreting gene expression data, such as microarray, RNA seq data, etc. The advantage of GSEA over other methods is that, instead of focusing on analysis of single genes, it performs the analysis of a *group of genes*. In this way, changes in pathways reflected through small, but coordinated change of several genes can be detected, leading to potential elucidation of biologically significant changes relevant for eg. process of carcinogenesis. #### Gene sets ______ By using GSEA, we are actually trying to put our obtained results of differential expression into the previous, already known biological context. This is achieved by using the *gene sets*, which represent group of genes that are grouped together based on their common biological function and/or involvement in the same biological pathways. Those gene sets are formed according to already published biological data containing biochemical pathways or coexpression of functionally related genes. They are publicly available in the form of Molecular Signatures Database (MSigDB) on the [Broad Institute](http://software.broadinstitute.org/gsea/msigdb/collections.jsp) web page. #### GSEA principle _________ >Gene Set Enrichment Analysis (GSEA) is a computational method that determines whether an a priori defined set of genes shows statistically significant, concordant differences between two biological states (e.g. phenotypes). Definition taken from official [GSEA user guide](http://software.broadinstitute.org/gsea/doc/GSEAUserGuideFrame.html), because there's no other way to explain mathematical method behind the analysis. The algorithm used is fully described in this [paper](http://software.broadinstitute.org/gsea/doc/subramanian_tamayo_gsea_pnas.pdf), and it's based on weighted Kolmogorov–Smirnov-like statistics. Luckily for us biologists, our friends mathematicians have developed a user-friendly software, that performs analysis for us, the "only" thing we need to do is to prepare input files with our data in the form that will be recognized by the software. In the following lines I have prepared a detailed guideline on how to prepare your data and run GSEA. #### GSEA Tutorial __________ <div class=pull-left>  <center> <sup>[Java](https://commons.wikimedia.org/wiki/File:Java.png), public domain</sup> </center> </div> <div class=pull-right> GSEA Software runs on Java, so before downloading and installing software, you need to make sure that you have Java 8 installed on your computer. Very important information - GSEA Software is available is several memory configurations: **1, 2, 4** and **8 GB**. GSEA of 1 GB can be used with 32- or 64-bit Java 8, other configurations require 64-bit Java 8 only! </div> <br><br><br><br> <br><br><br><br><br><br><br><br><br> If you run 64-bit operative system (Windows) on your computer, I recommend you to install 64-bit Java 8 and GSEA with higher memory configurations (2, 4 or 8 GB). Of course, you have to choose a memory configuration *smaller* than total RAM memory of your computer! This has one very important practical implication - when you're analyzing very large data sets (eg. more than 10 000 genes) and using databases with large number of gene sets (we'll come to that later), it often happens that Java runs out of memory, and GSEA Software cannot perform the analysis. For example, my laptop has 8 GB RAM, 64-bit Windows 7 Ultimate, and I'm running 4 GB GSEA (quite enough for all the analyses I performed). After you have installed Java 8, you can head to [GSEA Downloads](http://software.broadinstitute.org/gsea/downloads.jsp) page and download one of the GSEA Software configurations. **Note - you will have to register to be able to access downloads page, your e-mail is required only.** <center></center> <center>*GSEA Downloads page*</center> **Running the software** If you've successfully installed your GSEA Software, after launching it the main window opens, and it should look something like this: 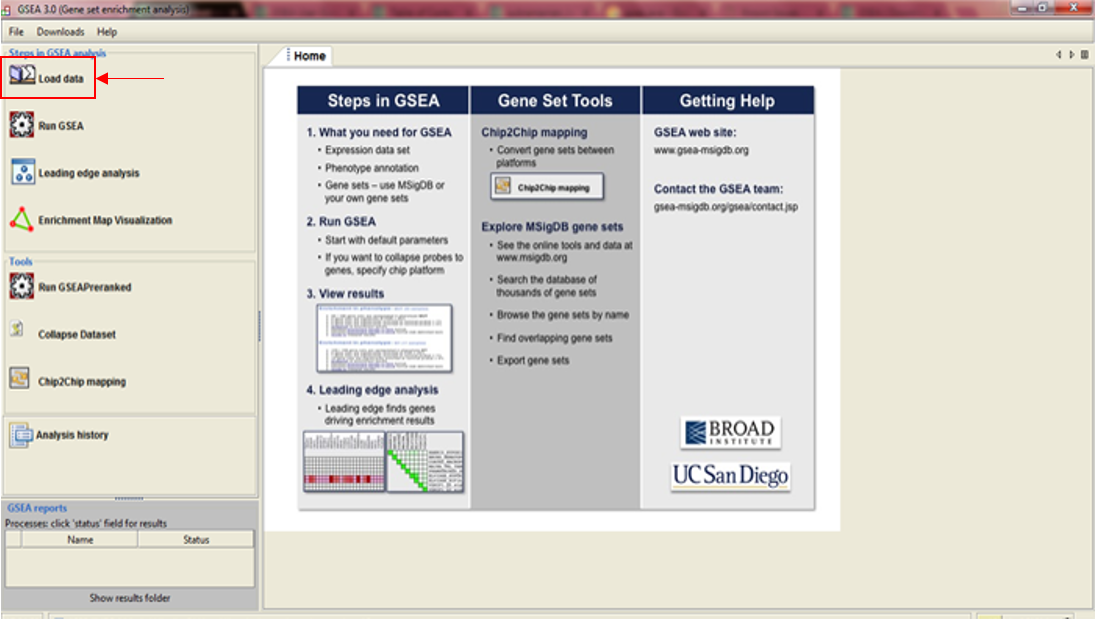 In the upper left corner click on *Load data*, and the following window opens: 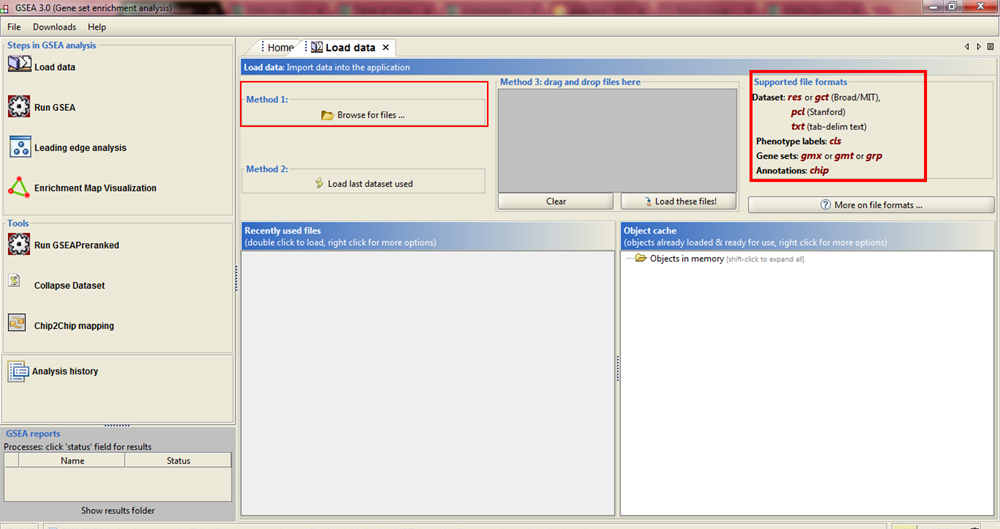 Now we have arrived at the most important part of GSEA analysis - **transforming your data into the GSEA input files**. I'm saying this is the most important part because if you fail to create input files in proper format(s) acceptable by the GSEA, the software will report an error after you load the files and you won't be able to run your analysis. So pay close attention! :) If you take a closer look at the upper right part of the last image, you will see that software informs you about the acceptable data formats, Basically, it is essential that you have prepared the following two file formats before running your analysis: **1. Expression data set file** (there are several options, but *.gct file* works perfectly fine for me) - this is your expression data set, actual data you obtained after performing RNA seq analysis **2. Phenotype labels file** (*.cls file*) **Preparing .gct file** Usually your RNA seq data is contained (after initial processing) in one or more Excel files (you can see how it looks in my previous [post](https://steemit.com/steemstem/@scienceangel/lab-diaries-4-whole-transcriptome-and-proteome-analysis-by-rna-sequencing-and-tmt-ms). To be able to analyse it in GSEA, you need to adapt it into something that GSEA Software can read and understand, and that's called *.gct file.* In the first step of creating your .gct file, open a blank Excel sheet and from your RNA seq data file copy and paste columns containing gene names and all replicates of your data. <center>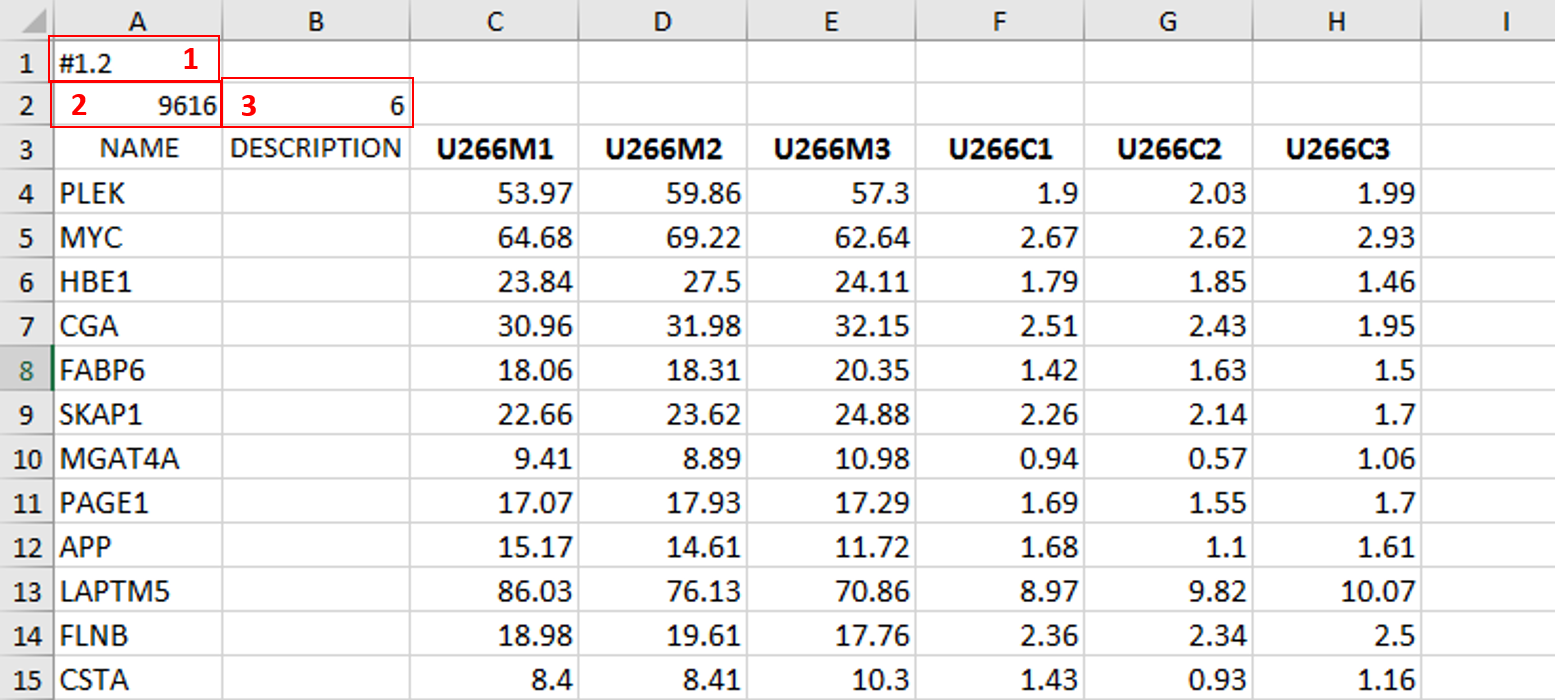</center> <center>*First step in creating a .gct file*</center> As you can see in the image, it is also necessary to have an additional column in between NAME and your replicates, which is called DESCRIPTION (I usually leave this column empty). In the first cell of the first row (number 1 in red) you need to write this **#1.2**, and this is what each .gct file must contain, it represents the version of .gct file and GSEA uses this particular version/form. In the first cell of the second row, you must input **the number of your genes contained in .gct file, genes that you're analyzing** (number 2 in red, in my example I had 9616 genes for the analysis). This is very important step, because if the number in this cell doesn't match the number of genes in .gct file, the software will report an error and won't work. Finally, in the second cell of the second row (number 3 in red) you need to input **the number of samples** you're analyzing. In my example, I had 6 samples - 2 triplicates. The order of samples matter as well, meaning that samples you're focusing your research on should be put first. In my example, I was interested in comparing expression in U266M samples with U266C samples (controls). When you have finished creating Excel .gct file and it looks like mine example from above, make sure you save it as Excel file first. Then you need to save it as **text (Tab delimited)** file as well. So now you should have two files - Excel and text file. Final step - open your text file and select Save as, then select All files, and just manually type extension at the end - .gct. You should now have three files in your GSEA folder: Excel, text and .gct file. **Preparing phenotype labels (.cls) file** Phenotype labels file serves to provide information to GSEA Software on how many samples your .gct file contains, how many *different phenotypes* and which phenotypes are located in which cells. Let's proceed to example immediately: <center>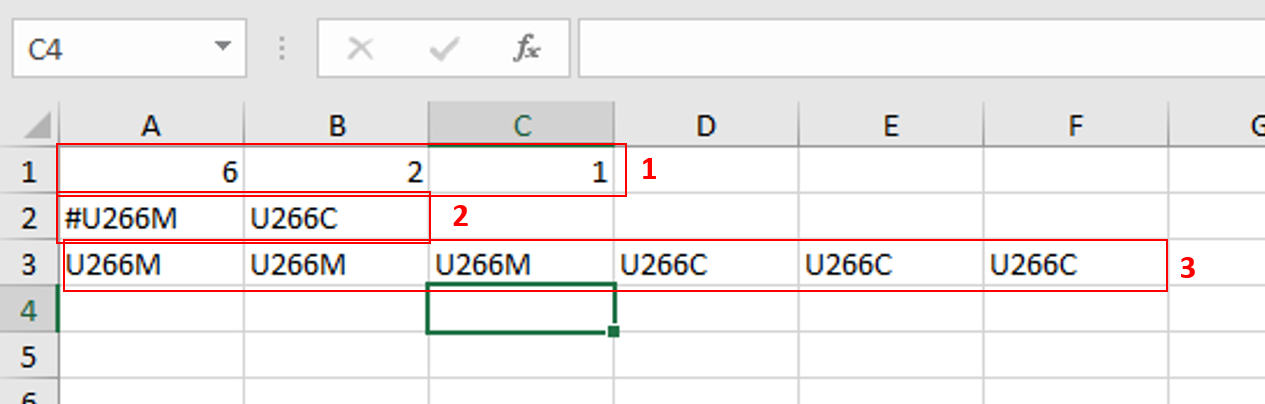</center> <center>*First step in creating .cls file*</center> In the first row you can see following numbers: 6, 2 and 1. 6 represents number of samples you have. 2 represents number of different phenotypes you're analyzing. That means - tumor vs. control tissue, treated vs. non-treated cells, transformed vs. non-transformed cells. All examples of different phenotypes/states in your experiment. 1 is always 1, I actually don't know why :) Second row (number 2 in red) tells to GSEA Software how your phenotypes are labeled, so the software can have information on what is one and what is another phenotype. This sign "#" must precede the first phenotype label (in the first cell of the second row). Finally, third row (number 3 in red) provides information to software how many samples of each phenotype are being analyzed. In my example, 3 samples of phenotype U266M and 3 samples of phenotype U266C. The rest of the steps are the same as in creation of .gct file - first make sure that you save your Excel file of .cls file. Then save it as Tab delimited text file. Finally, open the text file and change the extension to .cls. At the end you should have three files - Excel, text and .cls file. In the Part II I will explain how to perform GSEA using files you created using this tutorial. Until then, relax and keep steemSTEM! ;) ________ Literature [1] [Subramanian, A., Tamayo, P., Mootha, V. K., Mukherjee, S., Ebert, B. L., Gillette, M. A., ... & Mesirov, J. P. (2005). Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proceedings of the National Academy of Sciences, 102(43), 15545-15550.](http://software.broadinstitute.org/gsea/doc/subramanian_tamayo_gsea_pnas.pdf) [2] [GSEA User Guide](http://software.broadinstitute.org/gsea/doc/GSEAUserGuideFrame.html) [3] [Java heap space / OutOfMemoryError](http://software.broadinstitute.org/cancer/software/gsea/wiki/index.php/Known_Issues) -------------- <center>**For more scientific-related content check [steemSTEM](https://steemit.com/trending/steemstem). Follow me if you like my posts and want to read some more ;) If you have any thoughts/suggestions fell free to leave a comment!**</center> <center></center> <center>**Special thanks to wonderful and incredibly talented @atopy, who authored this amazing artwork for me, make sure to check out her blog!!!**</center>
| post_id | 43,731,741 |
|---|---|
| author | scienceangel |
| permlink | lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i |
| category | steemstem |
| json_metadata | "{"links": ["https://steemit.com/steemstem/@scienceangel/lab-diaries-4-whole-transcriptome-and-proteome-analysis-by-rna-sequencing-and-tmt-ms", "https://en.wikipedia.org/wiki/File:Signal_transduction_pathways.svg", "https://creativecommons.org/licenses/by-sa/3.0/deed.en", "http://software.broadinstitute.org/gsea/msigdb/collections.jsp", "http://software.broadinstitute.org/gsea/doc/GSEAUserGuideFrame.html", "http://software.broadinstitute.org/gsea/doc/subramanian_tamayo_gsea_pnas.pdf", "https://commons.wikimedia.org/wiki/File:Java.png", "http://software.broadinstitute.org/gsea/downloads.jsp", "http://software.broadinstitute.org/cancer/software/gsea/wiki/index.php/Known_Issues", "https://steemit.com/trending/steemstem"], "users": ["atopy"], "tags": ["steemstem", "steemeducation", "science", "biology", "life"], "app": "steemit/0.1", "image": ["https://steemitimages.com/DQmVXY2AwNSYcZCUp9Kvyki9oiFoBaGBgcwRuB8CxQo6rSM/Picture2.png"], "format": "markdown"}" |
| created | 2018-04-15 16:24:54 |
| last_update | 2018-04-15 16:24:54 |
| depth | 0 |
| children | 17 |
| net_rshares | 18,320,723,437,871 |
| last_payout | 2018-04-22 16:24:54 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 71.591 SBD |
| curator_payout_value | 21.828 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 13,487 |
| author_reputation | 113,646,366,638,572 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| pharesim | 0 | 76,668,108,076 | 0.09% | ||
| lafona-miner | 0 | 1,368,170,709,585 | 60% | ||
| kushed | 0 | 162,417,824,968 | 10.8% | ||
| steem-id | 0 | 91,562,314,829 | 10.8% | ||
| kevinwong | 0 | 115,033,095,106 | 1.62% | ||
| justtryme90 | 0 | 2,547,851,553,492 | 100% | ||
| eric-boucher | 0 | 19,615,814,470 | 5.4% | ||
| anwenbaumeister | 0 | 271,593,944,455 | 10.8% | ||
| grandpere | 0 | 148,029,901,232 | 60% | ||
| arconite | 0 | 602,863,195 | 0.81% | ||
| remlaps | 0 | 17,427,994,963 | 100% | ||
| timsaid | 0 | 53,717,681,663 | 12% | ||
| velourex | 0 | 4,257,539,079 | 10.8% | ||
| lemouth | 0 | 184,690,398,920 | 42% | ||
| rjbauer85 | 0 | 3,430,797,387 | 60% | ||
| anarchyhasnogods | 0 | 96,131,691,648 | 30% | ||
| etcmike | 0 | 22,631,089,278 | 10% | ||
| lamouthe | 0 | 14,581,009,694 | 60% | ||
| stevenwalkerrr | 0 | 277,462,365 | 10.8% | ||
| steemedia | 0 | 1,173,254,521 | 10.8% | ||
| curie | 0 | 495,111,254,692 | 10.8% | ||
| cebymaster | 0 | 1,463,620,256 | 10.8% | ||
| vannour | 0 | 996,902,247 | 1% | ||
| hendrikdegrote | 0 | 4,902,257,464,265 | 10.8% | ||
| jaki01 | 0 | 2,513,332,750,876 | 100% | ||
| steemworld | 0 | 108,365,468 | 1% | ||
| steemstem | 0 | 1,547,471,372,461 | 60% | ||
| dashfit | 0 | 1,030,105,991 | 5.4% | ||
| sethroot | 0 | 123,969,816 | 1.08% | ||
| cotidiana | 0 | 1,306,182,621 | 10.8% | ||
| brobear1995 | 0 | 170,450,263 | 5.4% | ||
| foundation | 0 | 5,404,483,636 | 60% | ||
| the-devil | 0 | 7,216,653,305 | 60% | ||
| timothyb | 0 | 77,637,848,586 | 100% | ||
| thevenusproject | 0 | 30,892,698,205 | 60% | ||
| kobold-djawa | 0 | 138,355,423,328 | 100% | ||
| dna-replication | 0 | 15,704,466,004 | 60% | ||
| lenin-mccarthy | 0 | 305,008,328 | 5.4% | ||
| jgpro | 0 | 94,867,491 | 5.4% | ||
| boynashruddin | 0 | 327,849,198 | 5% | ||
| heriafriadiaka | 0 | 145,097,512 | 10.8% | ||
| dyancuex | 0 | 102,159,901 | 5.4% | ||
| pacokam8 | 0 | 420,448,684 | 2.7% | ||
| borislavzlatanov | 0 | 4,765,457,791 | 60% | ||
| lordneroo | 0 | 5,860,531,369 | 100% | ||
| jamhuery | 0 | 6,154,526,160 | 60% | ||
| davidorcamuriel | 0 | 1,336,848,939,421 | 100% | ||
| jdc | 0 | 80,062,381 | 1.08% | ||
| replichara | 0 | 20,762,138,620 | 100% | ||
| jacalf | 0 | 79,325,363 | 10.8% | ||
| mobbs | 0 | 159,304,430,810 | 50% | ||
| kryzsec | 0 | 25,042,200,058 | 60% | ||
| markangeltrueman | 0 | 1,341,126,917 | 1.62% | ||
| nedspeaks | 0 | 11,887,972,658 | 60% | ||
| odic3o1 | 0 | 133,770,675 | 6% | ||
| lrsm13 | 0 | 101,265,674 | 3.24% | ||
| tantawi | 0 | 818,233,240 | 10.8% | ||
| trumpman | 0 | 200,756,393,105 | 56% | ||
| robertvogt | 0 | 2,140,631,152 | 10.8% | ||
| locikll | 0 | 4,440,782,183 | 21.6% | ||
| dber | 0 | 23,652,654,927 | 60% | ||
| aboutyourbiz | 0 | 2,003,836,150 | 10.8% | ||
| dreamien | 0 | 574,414,418 | 10.8% | ||
| kerriknox | 0 | 149,562,059,005 | 60% | ||
| alexander.alexis | 0 | 25,913,818,277 | 100% | ||
| howtostartablog | 0 | 189,112,322 | 0.54% | ||
| jonmagnusson | 0 | 11,830,244,763 | 50% | ||
| blessing97 | 0 | 1,803,990,456 | 60% | ||
| suesa | 0 | 349,502,159,791 | 100% | ||
| slickhustler007 | 0 | 453,218,843 | 5.4% | ||
| rockeynayak | 0 | 344,390,611 | 60% | ||
| ertwro | 0 | 20,672,013,918 | 60% | ||
| makrotheblack | 0 | 314,200,423 | 5.4% | ||
| coloringiship | 0 | 167,774,236 | 0.54% | ||
| thinknzombie | 0 | 15,651,435,251 | 5.4% | ||
| nitesh9 | 0 | 13,880,636,270 | 60% | ||
| churchboy | 0 | 8,930,814,876 | 60% | ||
| jpederson96 | 0 | 74,206,742 | 1.5% | ||
| gambit.coin | 0 | 137,800,915 | 10.8% | ||
| mcw | 0 | 3,924,925,849 | 10% | ||
| himal | 0 | 4,278,512,822 | 60% | ||
| nitego | 0 | 257,140,689 | 3.24% | ||
| shebe | 0 | 226,084,656 | 5.4% | ||
| bachuslib | 0 | 18,590,783,874 | 100% | ||
| abigail-dantes | 0 | 425,155,585,957 | 25% | ||
| leczy | 0 | 3,217,362,300 | 60% | ||
| phogyan | 0 | 292,257,205 | 5.4% | ||
| ovij | 0 | 8,470,434,378 | 60% | ||
| suravsingh | 0 | 732,717,701 | 60% | ||
| krazypoet | 0 | 83,764,202 | 0.05% | ||
| joseg | 0 | 552,487,030 | 36% | ||
| kofspades | 0 | 69,241,545 | 5.4% | ||
| atopy | 0 | 15,174,551,756 | 50% | ||
| mountain.phil28 | 0 | 2,720,722,249 | 25% | ||
| akeelsingh | 0 | 2,177,106,468 | 60% | ||
| mountainwashere | 0 | 20,285,185,523 | 60% | ||
| leyla5 | 0 | 161,762,773 | 5.4% | ||
| muliadi | 0 | 120,162,556 | 5.4% | ||
| somethingburger | 0 | 5,952,196,638 | 60% | ||
| purepinay | 0 | 23,838,725,225 | 5% | ||
| zest | 0 | 40,729,127,434 | 100% | ||
| felixrodriguez | 0 | 1,378,056,479 | 30% | ||
| dysprosium | 0 | 19,931,663,985 | 100% | ||
| tormiwah | 0 | 2,047,650,881 | 18% | ||
| gabox | 0 | 174,280,073 | 0.54% | ||
| djlethalskillz | 0 | 1,109,991,832 | 5% | ||
| runningman | 0 | 101,173,183 | 5.4% | ||
| infinitelearning | 0 | 349,837,055 | 5.4% | ||
| massivevibration | 0 | 4,943,574,109 | 5% | ||
| onartbali | 0 | 755,227,385 | 5% | ||
| clweeks | 0 | 423,710,320 | 4.32% | ||
| circleoffriends | 0 | 65,350,004 | 5.4% | ||
| bssman | 0 | 2,377,368,637 | 30% | ||
| simplifylife | 0 | 8,305,339,829 | 30% | ||
| smafey | 0 | 122,571,947 | 5.4% | ||
| marialefleitas | 0 | 136,436,176 | 5.4% | ||
| damzxyno | 0 | 64,475,155 | 3.24% | ||
| jordanx2 | 0 | 534,688,260 | 5.4% | ||
| birgitt | 0 | 300,499,621 | 10.8% | ||
| mayowadavid | 0 | 3,566,389,590 | 30% | ||
| imamalkimas | 0 | 486,205,801 | 10.8% | ||
| zeeshan003 | 0 | 1,239,569,947 | 60% | ||
| ahmadnayan | 0 | 61,367,672 | 5.4% | ||
| farive | 0 | 57,973,062 | 100% | ||
| martis6 | 0 | 599,713,136 | 100% | ||
| enzor | 0 | 961,253,254 | 30% | ||
| rmz | 0 | 56,963,421 | 5.4% | ||
| bobdos | 0 | 578,012,194 | 1.08% | ||
| jesusj1 | 0 | 117,535,675 | 5.4% | ||
| digitalpnut | 0 | 168,587,724 | 5.4% | ||
| carloserp-2000 | 0 | 10,085,748,297 | 60% | ||
| pangoli | 0 | 4,968,999,201 | 60% | ||
| rachelsmantra | 0 | 2,381,605,813 | 60% | ||
| gra | 0 | 19,114,802,949 | 60% | ||
| wandersells | 0 | 63,818,492 | 5.4% | ||
| ifartrainbows | 0 | 350,046,396 | 15% | ||
| exercisinghealth | 0 | 33,498,040,379 | 100% | ||
| sci-guy | 0 | 143,798,370 | 60% | ||
| kerry234 | 0 | 125,106,498 | 10.8% | ||
| renderlife | 0 | 587,636,781 | 100% | ||
| dailypick | 0 | 574,775,991 | 100% | ||
| ibrik | 0 | 596,186,208 | 100% | ||
| katerinaramm | 0 | 9,176,270,539 | 34% | ||
| karolisp | 0 | 50,564,630 | 0.1% | ||
| delph-in-holland | 0 | 116,015,875 | 5.4% | ||
| babangsunan | 0 | 80,768,522 | 100% | ||
| motivatorjoshua | 0 | 142,097,265 | 10.8% | ||
| meetmysuperego | 0 | 283,921,899 | 2.7% | ||
| sireh | 0 | 937,714,672 | 2.16% | ||
| physics.benjamin | 0 | 9,639,835,959 | 100% | ||
| xanderslee | 0 | 522,795,515 | 10.8% | ||
| egotheist | 0 | 9,589,937,546 | 100% | ||
| kenadis | 0 | 15,045,201,876 | 60% | ||
| amavi | 0 | 9,369,020,630 | 12% | ||
| enjoyy | 0 | 54,386,391 | 5.4% | ||
| robotics101 | 0 | 5,487,271,071 | 100% | ||
| tristan-muller | 0 | 482,370,137 | 60% | ||
| paulthebeloved | 0 | 76,190,370 | 5.4% | ||
| jaeydallah | 0 | 148,559,952 | 10.8% | ||
| alexs1320 | 0 | 33,278,744,138 | 100% | ||
| deanhass | 0 | 2,841,083,432 | 100% | ||
| gentleshaid | 0 | 13,267,792,300 | 60% | ||
| zalandir | 0 | 399,471,780 | 2.16% | ||
| crescendoofpeace | 0 | 143,227,787 | 5.4% | ||
| tito36 | 0 | 57,547,743 | 10.8% | ||
| sco | 0 | 34,208,558,742 | 100% | ||
| adetola | 0 | 2,380,212,901 | 60% | ||
| evernew | 0 | 57,460,241 | 5.4% | ||
| dysfunctional | 0 | 2,118,630,692 | 30% | ||
| rasamuel | 0 | 127,753,940 | 5.4% | ||
| thedrewshow | 0 | 68,939,708 | 10.8% | ||
| cordeta | 0 | 181,017,141 | 5.4% | ||
| cerventus | 0 | 80,408,459 | 5.4% | ||
| monie | 0 | 483,817,321 | 100% | ||
| speaklife | 0 | 134,497,219 | 10.8% | ||
| laritheghost | 0 | 138,844,016 | 5.4% | ||
| bimijay | 0 | 52,259,759 | 10.8% | ||
| whileponderin | 0 | 1,546,600,459 | 60% | ||
| jlmol7 | 0 | 149,829,353 | 30% | ||
| mittymartz | 0 | 4,244,817,251 | 30% | ||
| bennettitalia | 0 | 192,534,183 | 0.54% | ||
| hadji | 0 | 2,698,633,749 | 60% | ||
| sakura1012 | 0 | 1,231,997,255 | 60% | ||
| scienceangel | 0 | 16,567,625,975 | 100% | ||
| adebayopaul | 0 | 61,631,641 | 10.8% | ||
| sikan-eyen | 0 | 67,350,606 | 10.8% | ||
| mrxplicit | 0 | 57,487,425 | 10.8% | ||
| fidelpoet | 0 | 456,133,985 | 10.8% | ||
| terrylovejoy | 0 | 8,176,118,583 | 24% | ||
| victoryudofia | 0 | 161,630,333 | 10.8% | ||
| neneandy | 0 | 444,793,600 | 10.8% | ||
| strings | 0 | 119,846,713 | 5.4% | ||
| giddyupngo | 0 | 149,818,544 | 5.4% | ||
| steepup | 0 | 371,000,706 | 24% | ||
| zoricatech | 0 | 1,366,358,897 | 100% | ||
| aaronteng | 0 | 82,570,894 | 5.4% | ||
| debbietiyan | 0 | 219,383,691 | 5.4% | ||
| rionpistorius | 0 | 1,184,642,653 | 30% | ||
| srikandi | 0 | 1,139,373,426 | 100% | ||
| heajin | 0 | 67,407,423 | 15% | ||
| deutsch-boost | 0 | 383,724,339 | 20% | ||
| kingabesh | 0 | 971,173,138 | 100% | ||
| wdoutjah | 0 | 492,263,148 | 5.4% | ||
| modernmclaire | 0 | 61,310,185 | 10.8% | ||
| jpmkikoy | 0 | 102,835,123 | 5.4% | ||
| caitycat | 0 | 170,502,372 | 5.4% | ||
| dexterdev | 0 | 12,990,118,173 | 60% | ||
| gio6 | 0 | 221,483,446 | 5.4% | ||
| loydjayme25 | 0 | 72,335,847 | 5.4% | ||
| ugonma | 0 | 804,206,376 | 60% | ||
| lintang | 0 | 1,236,478,329 | 100% | ||
| ajpacheco1610 | 0 | 374,190,762 | 30% | ||
| drkomoo | 0 | 685,425,676 | 60% | ||
| v1tko | 0 | 54,783,257 | 5.4% | ||
| liberviarum | 0 | 3,927,276,216 | 100% | ||
| benleemusic | 0 | 1,347,406,144 | 0.54% | ||
| procrastilearner | 0 | 11,209,036,193 | 42% | ||
| kul0tzzz | 0 | 55,091,384 | 10.8% | ||
| chimtivers96 | 0 | 555,810,857 | 10.8% | ||
| zipporah | 0 | 607,245,650 | 2.16% | ||
| jerscoguth | 0 | 67,595,010 | 10.8% | ||
| amirdesaingrafis | 0 | 67,594,566 | 5.4% | ||
| wrpx | 0 | 60,335,034 | 5.4% | ||
| anyes2013 | 0 | 356,846,879 | 30% | ||
| jaycem | 0 | 116,442,320 | 19.2% | ||
| positiveninja | 0 | 897,920,676 | 5.4% | ||
| the-doubled | 0 | 58,167,720 | 10.8% | ||
| e-troubled | 0 | 61,350,891 | 10.8% | ||
| theunlimited | 0 | 52,227,985 | 10% | ||
| chillingotter | 0 | 1,125,310,942 | 5.4% | ||
| acknowledgement | 0 | 939,403,402 | 10% | ||
| simplicitytech | 0 | 165,085,914 | 30% | ||
| mrgranville | 0 | 54,788,096 | 10.8% | ||
| pseudojew | 0 | 932,915,336 | 60% | ||
| yu-stem | 0 | 2,203,890,302 | 100% | ||
| effofex | 0 | 673,293,926 | 30% | ||
| wisata | 0 | 67,590,811 | 10.8% | ||
| mrbreeziewrites | 0 | 1,398,672,018 | 100% | ||
| count-antonio | 0 | 150,065,020 | 30% | ||
| victorcovrig | 0 | 69,789,876 | 1% | ||
| de-stem | 0 | 20,268,803,861 | 48% | ||
| ikeror | 0 | 58,348,540 | 9.72% | ||
| serylt | 0 | 8,719,646,508 | 48% | ||
| ari16 | 0 | 185,651,264 | 30% | ||
| bukfast | 0 | 519,158,553 | 100% | ||
| qiyi | 0 | 1,671,335,281 | 100% | ||
| blockmountain | 0 | 198,522,587 | 3.24% | ||
| sigmund | 0 | 55,808,617 | 5.4% | ||
| foniz | 0 | 100,435,402 | 10.8% | ||
| irelandscape | 0 | 806,317,116 | 100% | ||
| i-have-tested | 0 | 58,115,700 | 10.8% | ||
| maywether | 0 | 0 | 100% | ||
| aarontaggert | 0 | 83,588,500 | 10.8% | ||
| etaletai | 0 | 69,105,137 | 5.4% | ||
| the-tourist | 0 | 61,547,569 | 10.8% | ||
| trpolice | 0 | 50,065,761 | 10.8% | ||
| doctor-cog-diss | 0 | 255,926,015 | 100% | ||
| romanleopold | 0 | 143,467,897 | 5.4% | ||
| niouton | 0 | 644,877,851 | 2.16% | ||
| soundworks | 0 | 92,863,382 | 8.36% | ||
| nqian2 | 0 | 517,577,807 | 100% | ||
| beautyinscience | 0 | 180,691,097 | 30% | ||
| star-vc | 0 | 342,646,242 | 60% | ||
| kehrwoche | 0 | 464,476,383 | 100% | ||
| kayannepepper | 0 | 599,618,954 | 100% | ||
| biomimi | 0 | 214,148,552 | 40% |
This is absolutely perfect! The best HowTo that could be found on the internet. Students should learn from this. I can't wait for the Part III or II depending how you count
| post_id | 43,732,596 |
|---|---|
| author | alexs1320 |
| permlink | re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180415t163103393z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-15 16:31:03 |
| last_update | 2018-04-15 16:31:24 |
| depth | 1 |
| children | 0 |
| net_rshares | 15,894,828,981 |
| last_payout | 2018-04-22 16:31:03 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.078 SBD |
| curator_payout_value | 0.000 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 173 |
| author_reputation | 149,050,464,338,619 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| scienceangel | 0 | 15,894,828,981 | 100% |
I like the new artwork. @atopy did a great job! Also, great breakdown of GSEA. Its a useful tool, but even with its help its difficult to interpret large datasets like this.
| post_id | 43,746,799 |
|---|---|
| author | tking77798 |
| permlink | re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180415t182324800z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "users": ["atopy"], "tags": ["steemstem"]}" |
| created | 2018-04-15 18:23:27 |
| last_update | 2018-04-15 18:23:27 |
| depth | 1 |
| children | 1 |
| net_rshares | 15,105,263,098 |
| last_payout | 2018-04-22 18:23:27 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.057 SBD |
| curator_payout_value | 0.018 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 177 |
| author_reputation | 14,491,425,587,942 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| tking77798 | 0 | 15,105,263,098 | 100% |
Exactly, it's always challenging finding the answers from these type of datasets. As a matter of fact, I'm still dealing with this :)
| post_id | 43,748,049 |
|---|---|
| author | scienceangel |
| permlink | re-tking77798-re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180415t183342163z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-15 18:33:39 |
| last_update | 2018-04-15 18:33:39 |
| depth | 2 |
| children | 0 |
| net_rshares | 14,786,769,548 |
| last_payout | 2018-04-22 18:33:39 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.054 SBD |
| curator_payout_value | 0.018 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 133 |
| author_reputation | 113,646,366,638,572 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| tking77798 | 0 | 14,786,769,548 | 100% |
>In each of our cells there are many, many (and one more time - many!) signal transduction pathways that include thousands of proteins, lol, the one more time. True
| post_id | 43,771,420 |
|---|---|
| author | vanessahampton |
| permlink | re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180415t223422371z |
| category | steemstem |
| json_metadata | "{"app": "busy/2.4.0", "community": "busy", "tags": ["steemstem"]}" |
| created | 2018-04-15 22:34:36 |
| last_update | 2018-04-15 22:34:36 |
| depth | 1 |
| children | 0 |
| net_rshares | 0 |
| last_payout | 2018-04-22 22:34:36 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.000 SBD |
| curator_payout_value | 0.000 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 166 |
| author_reputation | 3,362,533,862,951 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
Hey @scienceangel, thank you for your contributions! This is a wonderful blog. > In each of our cells there are many, many (and one more time - many!) signal transduction pathways that include thousands of proteins, which are tightly regulated to keep our cells alive and functioning. In cancer cells, due to the activation of oncogenes, many of those pathways are deregulated to provide advantages to cancer cells over normal cells. So does that basically mean that the more protein we consume the more dangerous it can be for our health? (Don't get mad at me if that's a dumb question :P) Thank you so much for providing detailed information regarding the use of the GSEA software. Personally I'm an Engineer so I will never get to use this software, however I do appreciate you taking the time to create this tutorial as I know how vital this can be for young scientists in your field. (We all depend on software and tutorials :P) Please keep up the great work!
| post_id | 43,772,915 |
|---|---|
| author | lordneroo |
| permlink | re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180415t225042862z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "users": ["scienceangel"], "tags": ["steemstem"]}" |
| created | 2018-04-15 22:50:45 |
| last_update | 2018-04-15 22:50:45 |
| depth | 1 |
| children | 3 |
| net_rshares | 15,630,148,820 |
| last_payout | 2018-04-22 22:50:45 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.060 SBD |
| curator_payout_value | 0.018 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 968 |
| author_reputation | 213,796,208,950,223 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| scienceangel | 0 | 15,630,148,820 | 100% |
Thank you very much! Actually, it is a very good question. It is quite normal that we ingest a lot of things on daily basis that are not necessary/in excess for our organism/cells at given moment - too much water, salt, carbs, fats, proteins, etc. Our cells of course have mechanisms of keeping homeostasis of intracellular environment, so when we ingest too much proteins for example, they will be digested in our gastrointestinal tract down to amino acids, which then hit the bloodstream. Cells will take up the amount of amino acids they need (especially muscle cells), and the rest/excess amino acids will be broken down in the liver to form ammonia. The liver converts the ammonia into urea, because ammonia is toxic. At last, urea is excreted from the body through the kidneys. So when you ingest more proteins than your cells need, it will be just more work for your liver and kidneys :) There are studies connecting red/processed meat intake with the increased risk of bowel cancer. This is however, not due to increased protein intake, but due to carcinogens found in processed meat, and if we are talking about red, non-processed meat, some evidence suggest that chemicals formed during digestion may damage the cells that line the bowel. Other causes may be the fat content, and the way it is processed or cooked; or just because people who eat preferentially red meat usually have low intake of "protective foods" such as fruit and vegetables or wholegrain cereals. So take-home advice - make sure that you eat everything in moderate quantities (balanced diet), have plenty of physical activity, avoid smoking and drinking too much alcohol, and you'll be fine ;)
| post_id | 43,818,514 |
|---|---|
| author | scienceangel |
| permlink | re-lordneroo-re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180416t062142226z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-16 06:21:42 |
| last_update | 2018-04-16 06:21:42 |
| depth | 2 |
| children | 2 |
| net_rshares | 9,220,311,809 |
| last_payout | 2018-04-23 06:21:42 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.039 SBD |
| curator_payout_value | 0.006 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 1,676 |
| author_reputation | 113,646,366,638,572 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| lordneroo | 0 | 7,509,023,080 | 100% | ||
| effofex | 0 | 1,711,288,729 | 100% |
Hey, thank you SO much for taking the time to leave such a detailed response, I truly appreciate that! So even excessive water consumption can harm our health? I've been drinking TOO much water for years!! Should I worry? Again, thank you so much for providing such deep information in this thread! Your blog was spectacular to say the least, but you also wrote another mini post in response to my comment! Stay awesome!
| post_id | 43,869,600 |
|---|---|
| author | lordneroo |
| permlink | re-scienceangel-re-lordneroo-re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180416t134259473z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-16 13:43:00 |
| last_update | 2018-04-16 13:43:00 |
| depth | 3 |
| children | 1 |
| net_rshares | 0 |
| last_payout | 2018-04-23 13:43:00 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.000 SBD |
| curator_payout_value | 0.000 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 423 |
| author_reputation | 213,796,208,950,223 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
Interesting! Looks like we're in the same field of biomedical science and cellular/molecular biology. You have a new follower!
| post_id | 43,775,358 |
|---|---|
| author | qiyi |
| permlink | re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180415t232003764z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-15 23:20:06 |
| last_update | 2018-04-15 23:20:06 |
| depth | 1 |
| children | 0 |
| net_rshares | 15,372,509,004 |
| last_payout | 2018-04-22 23:20:06 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.057 SBD |
| curator_payout_value | 0.018 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 128 |
| author_reputation | 1,728,931,463,548 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| scienceangel | 0 | 15,372,509,004 | 100% |
Oh wow, this is prompting me to get my butt off Steemit during lunch and do some sideline research. It seems like gene sets have a pretty clear analog in 'functional guilds' in microbio. I wonder if anyone has translated the mathematics over into ecology.
| post_id | 43,899,162 |
|---|---|
| author | effofex |
| permlink | re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180416t171839830z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-16 17:18:42 |
| last_update | 2018-04-16 17:18:42 |
| depth | 1 |
| children | 4 |
| net_rshares | 49,812,117,431 |
| last_payout | 2018-04-23 17:18:42 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.243 SBD |
| curator_payout_value | 0.006 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 257 |
| author_reputation | 14,417,464,439,057 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| alexs1320 | 0 | 34,092,545,470 | 100% | ||
| scienceangel | 0 | 15,719,571,961 | 100% |
In ecology - they need us :D The most popular is an easy matrix algebra, "game of life" simulation Or they measure various parameters and need some multivariate analysis to obtain the conclusion And the latest fashion and the closest thing to your question is: [environmental DNA (eDNA)](https://www.sciencedirect.com/science/article/pii/S0006320714004443)
| post_id | 43,900,291 |
|---|---|
| author | alexs1320 |
| permlink | re-effofex-re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180416t172723617z |
| category | steemstem |
| json_metadata | "{"links": ["https://www.sciencedirect.com/science/article/pii/S0006320714004443"], "app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-16 17:27:24 |
| last_update | 2018-04-16 17:27:24 |
| depth | 2 |
| children | 3 |
| net_rshares | 1,542,965,247 |
| last_payout | 2018-04-23 17:27:24 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.000 SBD |
| curator_payout_value | 0.000 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 361 |
| author_reputation | 149,050,464,338,619 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| effofex | 0 | 1,542,965,247 | 100% |
I hear what you're saying, but ecological modelling has progressed far beyond Conway's game of life. * LTI systems modelling migration behavior * various ODE and PDE models of population dyanmics * ecological network inference and modelling (including keystone species prediction and syntrophic pair identification) etc
| post_id | 43,901,598 |
|---|---|
| author | effofex |
| permlink | re-alexs1320-re-effofex-re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180416t173817528z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-16 17:38:21 |
| last_update | 2018-04-16 17:38:21 |
| depth | 3 |
| children | 2 |
| net_rshares | 11,099,898,525 |
| last_payout | 2018-04-23 17:38:21 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.042 SBD |
| curator_payout_value | 0.012 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 322 |
| author_reputation | 14,417,464,439,057 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| alexs1320 | 0 | 11,099,898,525 | 33% |
This post has been upvoted and picked by [Daily Picked #31](https://steemit.com/curation/@dailypick/dailypick-31-16-april-or-explore-quality-content)! Thank you for the cool and quality content. Keep going! Don’t forget I’m not a robot. I explore, read, upvote and share manually ☺️
| post_id | 43,918,636 |
|---|---|
| author | dailypick |
| permlink | re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180416t195403216z |
| category | steemstem |
| json_metadata | "{"links": ["https://steemit.com/curation/@dailypick/dailypick-31-16-april-or-explore-quality-content"], "app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-16 19:54:03 |
| last_update | 2018-04-16 19:54:03 |
| depth | 1 |
| children | 0 |
| net_rshares | 0 |
| last_payout | 2018-04-23 19:54:03 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.000 SBD |
| curator_payout_value | 0.000 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 284 |
| author_reputation | 484,792,123,942 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
Congratulations @scienceangel! You have completed some achievement on Steemit and have been rewarded with new badge(s) : [](http://steemitboard.com/@scienceangel) Award for the number of upvotes received Click on any badge to view your own Board of Honor on SteemitBoard. For more information about SteemitBoard, click [here](https://steemit.com/@steemitboard) If you no longer want to receive notifications, reply to this comment with the word `STOP` > Upvote this notification to help all Steemit users. Learn why [here](https://steemit.com/steemitboard/@steemitboard/http-i-cubeupload-com-7ciqeo-png)!
| post_id | 43,922,183 |
|---|---|
| author | steemitboard |
| permlink | steemitboard-notify-scienceangel-20180416t202612000z |
| category | steemstem |
| json_metadata | "{"image": ["https://steemitboard.com/img/notifications.png"]}" |
| created | 2018-04-16 20:26:12 |
| last_update | 2018-04-16 20:26:12 |
| depth | 1 |
| children | 0 |
| net_rshares | 0 |
| last_payout | 2018-04-23 20:26:12 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.000 SBD |
| curator_payout_value | 0.000 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 692 |
| author_reputation | 38,705,954,145,809 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
Hell yah, that's one comprehensive and specific guideline. :) Unfortunatelly my recent biochem work does not need me to use it. -> But provides me with a lot of other problems ofc. Haha!
| post_id | 44,689,957 |
|---|---|
| author | mountain.phil28 |
| permlink | re-scienceangel-lab-diaries-5-gene-set-enrichment-analysis-gsea-of-a-large-scale-biological-data-part-i-20180421t143408874z |
| category | steemstem |
| json_metadata | "{"app": "steemit/0.1", "tags": ["steemstem"]}" |
| created | 2018-04-21 14:34:09 |
| last_update | 2018-04-21 14:34:24 |
| depth | 1 |
| children | 0 |
| net_rshares | 24,373,132,376 |
| last_payout | 2018-04-28 14:34:09 |
| cashout_time | 1969-12-31 23:59:59 |
| total_payout_value | 0.118 SBD |
| curator_payout_value | 0.034 SBD |
| pending_payout_value | 0.000 SBD |
| promoted | 0.000 SBD |
| body_length | 187 |
| author_reputation | 7,451,131,400,254 |
| root_title | "Lab Diaries #5 - Gene Set Enrichment Analysis (GSEA) of a Large-Scale Biological Data, Part I" |
| beneficiaries | [] |
| max_accepted_payout | 1,000,000.000 SBD |
| percent_steem_dollars | 10,000 |
| author_curate_reward | "" |
| voter | weight | wgt% | rshares | pct | time |
|---|---|---|---|---|---|
| mountain.phil28 | 0 | 8,503,390,962 | 100% | ||
| scienceangel | 0 | 15,869,741,414 | 100% |